· AIと機械学習 · 8 min read
Speech-to-Text API での音声認識の実装方法
Google Cloud の Speech-to-Text API を使用して、音声認識機能を実装する方法を詳しく解説します

Speech-to-Text API の概要
Google Cloud の Speech-to-Text API は、高度な機械学習モデルを使用して、音声をテキストに変換する強力なツールです。この API を使用することで、開発者は簡単に音声認識機能をアプリケーションに組み込むことができます。
Speech-to-Text API のユースケース
Speech-to-Text API は、様々な産業や用途で活用されています。以下に、いくつかの代表的なユースケースを紹介します:
1. カスタマーサービス:通話の自動文字起こし
コールセンターの通話内容を自動的にテキスト化することで、顧客とのやり取りを分析し、サービス品質の向上や効率化を図ることができます。
2. メディア制作:字幕・キャプションの自動生成
動画コンテンツやポッドキャストの音声を自動的にテキスト化し、字幕やキャプションを生成することで、アクセシビリティを向上させることができます。
3. 医療:診療記録の自動化
医師の音声による診療記録を自動的にテキスト化することで、記録作業の効率化と正確性の向上を実現できます。
4. 法律:法廷での証言の文字起こし
法廷での証言や弁論を自動的にテキスト化することで、正確な記録を効率的に作成し、法的プロセスをサポートできます。
5. 教育:講義の自動文字起こしと検索可能なアーカイブ作成
大学の講義や研修セッションを自動的にテキスト化し、検索可能なアーカイブを作成することで、学習効率を高めることができます。
6. 音声アシスタント:音声コマンドの処理
スマートホームデバイスや車載システムなどで、ユーザーの音声コマンドをテキストに変換し、適切な動作を実行することができます。
7. 会議:議事録の自動作成
ビジネスミーティングの内容を自動的にテキスト化し、効率的に議事録を作成することができます。これにより、参加者は会議の内容に集中し、後で簡単に内容を振り返ることができます。
プロジェクトのセットアップ
まず、Google Cloud Console でプロジェクトを作成し、Speech-to-Text API を有効にします。
- Google Cloud Console にアクセスし、新しいプロジェクトを作成します。
- 左側のメニューから「APIとサービス」→「ライブラリ」を選択します。
- 検索バーで「Speech-to-Text API」を検索し、有効にします。
認証情報の設定
API を使用するには、適切な認証情報が必要です。
- Google Cloud Console で「認証情報」ページに移動します。
- 「認証情報を作成」をクリックし、「サービスアカウント」を選択します。
- 必要な権限を付与し、JSONキーをダウンロードします。
Python環境のセットアップ
Pythonを使用して Speech-to-Text API を利用するアプリケーションを作成します。
pip install google-cloud-speech
音声認識アプリケーションの作成
以下は、基本的な音声認識アプリケーションの例です:
from google.cloud import speech
def transcribe_file(speech_file):
client = speech.SpeechClient()
with open(speech_file, "rb") as audio_file:
content = audio_file.read()
audio = speech.RecognitionAudio(content=content)
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=16000,
language_code="ja-JP",
)
response = client.recognize(config=config, audio=audio)
for result in response.results:
print("Transcript: {}".format(result.alternatives[0].transcript))
transcribe_file("path/to/your/audiofile.wav")
このスクリプトは、指定された音声ファイルを読み込み、Speech-to-Text API を使用してテキストに変換します。
高度な機能
Speech-to-Text API には、多くの高度な機能が用意されています:
- リアルタイム音声認識
- 複数の言語サポート
- 自動言語検出
- 話者ダイアライゼーション(複数話者の識別)
- 不適切な内容のフィルタリング
パフォーマンスの最適化
大量の音声データを処理する場合は、以下の最適化テクニックを検討してください:
- 長時間音声認識の使用
- バッチ処理の実装
- 適切な音声エンコーディングの選択
セキュリティの考慮事項
Speech-to-Text API を使用する際は、以下のセキュリティベストプラクティスを考慮することが重要です:
- APIキーの安全な管理
- 最小権限の原則の適用
- 音声データの暗号化
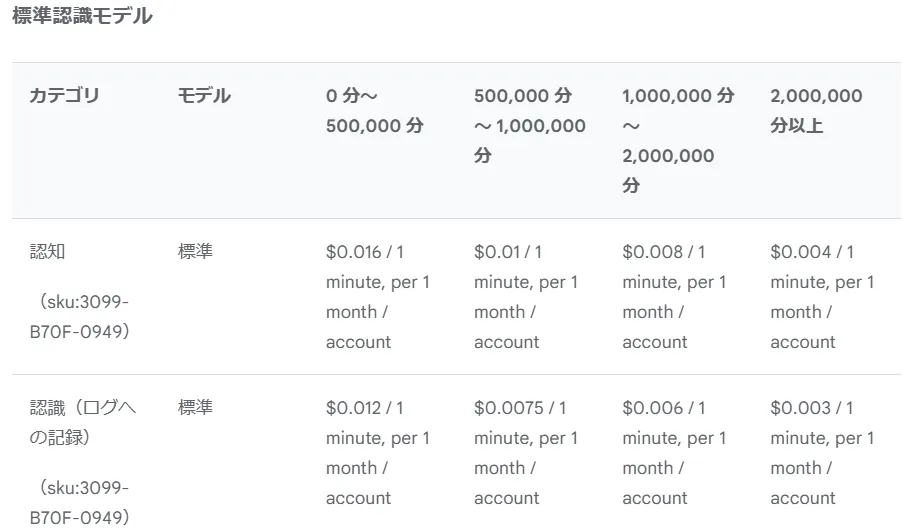
料金体系
Speech-to-Text API の料金は、処理する音声データの長さに基づいて計算されます。 長時間の音声認識や大量のデータ処理には、割引料金が適用される場合があります。
Speech-to-Text API の v1 と v2 の主な違い
Speech-to-Text API の v1 と v2 の主な違いを簡潔にまとめます
認識精度の向上: 最新の機械学習モデルにより、特にノイズの多い環境や複数話者の場面で改善。
言語サポートの拡大: より多くの言語とダイアレクトに対応。
カスタマイズ機能の強化: より柔軟な話者ダイアライゼーションやドメイン特化型の学習が可能に。
リアルタイム処理の改善: ストリーミング認識の遅延が低減。
マルチチャンネル音声認識: 複数のオーディオチャンネルを同時処理可能に。
API設計の刷新: より直感的で使いやすいインターフェースを提供。
高度なフィルタリング: 不適切な内容や特定キーワードのフィルタリング機能が向上。
詳細なメタデータ: 感情推定や音声品質評価などの情報が追加。
料金体系の改善: より柔軟で透明性の高い価格設定を導入。
これらの改善により、v2 はより高性能で使いやすい API となっています。
まとめ
Speech-to-Text API を使用することで、開発者は高度な音声認識機能を簡単にアプリケーションに統合できます。この API は継続的に改善されており、最新の自然言語処理技術の恩恵を受けることができます。
音声認識や自然言語処理について詳しく学びたい方には、以下の書籍がおすすめです:


