· AIと機械学習 · 7 min read
Cloud AI プラットフォームでの機械学習モデルのトレーニングと展開
Google Cloud AI Platform を使用して、機械学習モデルのトレーニングから展開までのプロセスを解説します。効率的なワークフローと最適なリソース管理方法を紹介します。

Google Cloud AI Platform の概要
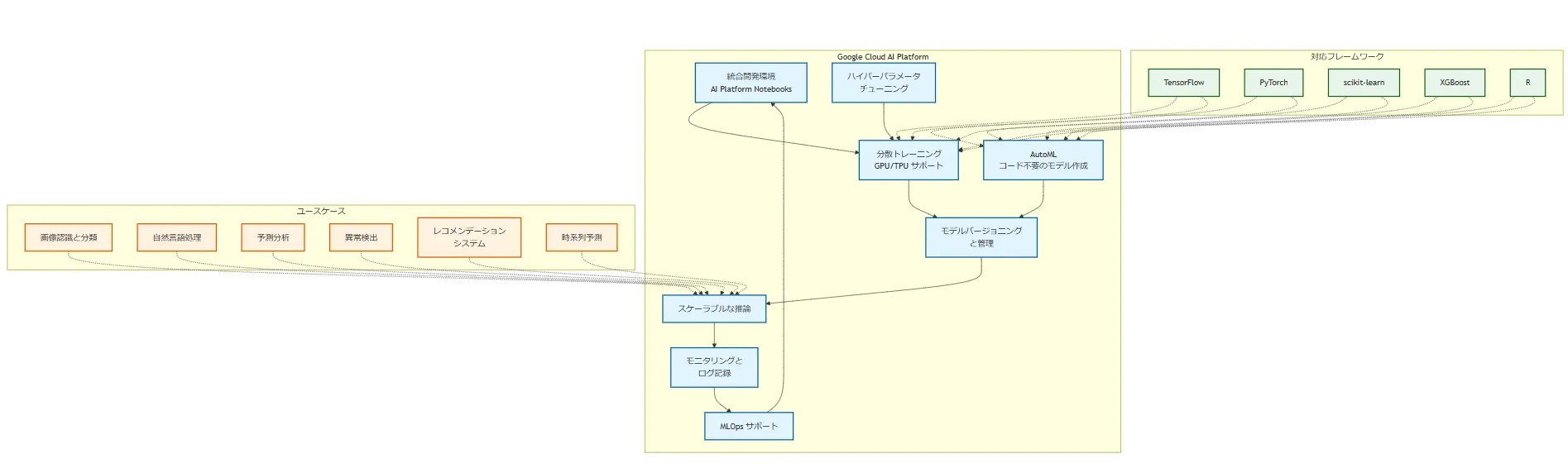
Google Cloud AI Platform は、機械学習モデルの開発、トレーニング、展開を効率的に行うための包括的な統合環境です。データサイエンティストや ML エンジニアが、スケーラブルなインフラストラクチャを活用して、高度な AI ソリューションを構築できるように設計されています。
主要な特徴
統合開発環境: Jupyter Notebook ベースの AI Platform Notebooks を提供し、コード開発からモデルのトレーニングまでをシームレスに行えます。
分散トレーニング: 大規模なデータセットに対して、複数の GPU や TPU を使用した分散トレーニングをサポートしています。
自動機械学習(AutoML): コードを書かずに高品質な機械学習モデルを作成できる AutoML 機能を提供しています。
ハイパーパラメータチューニング: モデルの性能を最適化するための自動ハイパーパラメータチューニング機能があります。
モデルバージョニングと管理: トレーニングしたモデルのバージョン管理や、A/B テストなどの高度な展開戦略をサポートしています。
スケーラブルな推論: トラフィックに応じて自動的にスケールする推論エンドポイントを提供します。
モニタリングとログ記録: 展開したモデルのパフォーマンスを継続的に監視し、詳細なログを記録できます。
MLOps サポート: CI/CD パイプラインとの統合や、モデルの継続的なトレーニングと展開をサポートしています。
対応フレームワーク
AI Platform は、以下の主要な機械学習フレームワークをサポートしています:
- TensorFlow
- PyTorch
- scikit-learn
- XGBoost
- R
ユースケース
AI Platform は幅広い業界や用途で活用されています:
- 画像認識と分類
- 自然言語処理
- 予測分析
- 異常検出
- レコメンデーションシステム
- 時系列予測
Google Cloud AI Platform を使用することで、データサイエンティストやML エンジニアは、インフラストラクチャの管理よりも、モデルの開発と改善に集中できます。また、エンタープライズレベルのセキュリティと、Google の先進的な AI 技術を活用することができます。
機械学習モデルのトレーニング
1. データの準備
まず、トレーニングデータを Cloud Storage にアップロードします。
from google.cloud import storage
def upload_blob(bucket_name, source_file_name, destination_blob_name):
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(destination_blob_name)
blob.upload_from_filename(source_file_name)
print(f"File {source_file_name} uploaded to {destination_blob_name}.")
upload_blob("my-ml-bucket", "local_training_data.csv", "training_data.csv")
2. モデルの定義
TensorFlow や scikit-learn などのフレームワークを使用してモデルを定義します。
import tensorflow as tf
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(10,)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1)
])
model.compile(optimizer='adam', loss='mse')
return model
model = create_model()
3. トレーニングジョブの設定
AI Platform でトレーニングジョブを設定し、実行します。
from google.cloud import aiplatform
aiplatform.init(project='your-project-id')
job = aiplatform.CustomTrainingJob(
display_name="my-training-job",
script_path="trainer/task.py",
container_uri="gcr.io/cloud-ml-pipeline-example/tensorflow-cpu",
requirements=["gcsfs==0.7.1"],
model_serving_container_image_uri="gcr.io/cloud-ml-pipeline-example/tensorflow-cpu"
)
model = job.run(
dataset=dataset,
base_output_dir=model_display_name,
args=[]
)
モデルの展開
1. モデルのエクスポート
トレーニングしたモデルを SavedModel 形式でエクスポートします。
model.save('saved_model/1/')
2. AI Platform にモデルをアップロード
from google.cloud import aiplatform
aiplatform.init(project='your-project-id')
model = aiplatform.Model.upload(
display_name="my-model",
artifact_uri="gs://my-bucket/saved_model/1/",
serving_container_image_uri="gcr.io/cloud-ml-pipeline-example/tensorflow-cpu"
)
3. エンドポイントの作成と展開
endpoint = aiplatform.Endpoint.create(display_name="my-endpoint")
endpoint.deploy(
model,
machine_type="n1-standard-4",
min_replica_count=1,
max_replica_count=5
)
エンドポイントの使用
エンドポイントを作成し、モデルを展開した後は、そのエンドポイントを使用して予測を行うことができます。以下に、エンドポイントの使用方法と実際の予測プロセスを説明します。
1. エンドポイントへのリクエスト
展開されたモデルに対して予測リクエストを送信するには、AI Platform の Python クライアントライブラリを使用します。
from google.cloud import aiplatform
def predict_custom_trained_model(
project: str,
endpoint_id: str,
instance_dict: dict,
location: str = "us-central1",
api_endpoint: str = "us-central1-aiplatform.googleapis.com",
):
client_options = {"api_endpoint": api_endpoint}
client = aiplatform.gapic.PredictionServiceClient(client_options=client_options)
instance = json_format.ParseDict(instance_dict, Value())
instances = [instance]
parameters_dict = {}
parameters = json_format.ParseDict(parameters_dict, Value())
endpoint = client.endpoint_path(
project=project, location=location, endpoint=endpoint_id
)
response = client.predict(
endpoint=endpoint, instances=instances, parameters=parameters
)
print("response")
print(" deployed_model_id:", response.deployed_model_id)
predictions = response.predictions
for prediction in predictions:
print(" prediction:", dict(prediction))
# 使用例
project_id = "your-project-id"
endpoint_id = "1234567890" # デプロイしたエンドポイントのID
instance = {"feature1": 1.0, "feature2": "example", "feature3": [1, 2, 3]}
predict_custom_trained_model(project_id, endpoint_id, instance)
2. バッチ予測
大量のデータに対して予測を行う場合は、バッチ予測を使用すると効率的です。
from google.cloud import aiplatform
def batch_predict(
project: str,
location: str,
instances_format: str,
gcs_source: str,
gcs_destination_prefix: str,
machine_type: str,
endpoint_id: str,
):
aiplatform.init(project=project, location=location)
endpoint = aiplatform.Endpoint(endpoint_id)
batch_prediction_job = endpoint.batch_predict(
job_display_name="batch_prediction",
gcs_source=gcs_source,
gcs_destination_prefix=gcs_destination_prefix,
instances_format=instances_format,
machine_type=machine_type,
)
batch_prediction_job.wait()
print(batch_prediction_job.display_name)
print(batch_prediction_job.resource_name)
print(batch_prediction_job.state)
# 使用例
project_id = "your-project-id"
location = "us-central1"
instances_format = "csv"
gcs_source = "gs://your-bucket/input-data.csv"
gcs_destination_prefix = "gs://your-bucket/predictions"
machine_type = "n1-standard-4"
endpoint_id = "1234567890"
batch_predict(
project_id,
location,
instances_format,
gcs_source,
gcs_destination_prefix,
machine_type,
endpoint_id,
)
3. リアルタイム予測の統合
Web アプリケーションやモバイルアプリにリアルタイム予測を統合する例を示します。
from flask import Flask, request, jsonify
from google.cloud import aiplatform
app = Flask(__name__)
def get_prediction(instance):
endpoint = aiplatform.Endpoint("projects/your-project-id/locations/us-central1/endpoints/1234567890")
prediction = endpoint.predict([instance])
return prediction.predictions[0]
@app.route('/predict', methods=['POST'])
def predict():
data = request.json
prediction = get_prediction(data)
return jsonify({'prediction': prediction})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8080)
この Flask アプリケーションは、/predict エンドポイントで POST リクエストを受け取り、AI Platform のエンドポイントを使用して予測を行い、結果を返します。
エンドポイントを使用することで、トレーニングしたモデルを本番環境で効果的に活用できます。単一の予測、バッチ予測、リアルタイム予測の統合など、様々なユースケースに対応できる柔軟性があります。また、AI Platform のスケーラビリティにより、トラフィックの増減に応じて自動的にリソースを調整することができます。
モデルの監視と最適化
1. パフォーマンスモニタリング
AI Platform のモニタリングダッシュボードを使用して、モデルのパフォーマンスを追跡します。
2. 自動スケーリング
トラフィックに応じて自動的にスケーリングするように設定します。
endpoint.deploy(
model,
machine_type="n1-standard-4",
min_replica_count=1,
max_replica_count=5,
autoscaling_target_cpu_utilization=70
)
3. モデルの更新
新しいデータでモデルを再トレーニングし、エンドポイントを更新します。
new_model = aiplatform.Model.upload(
display_name="my-updated-model",
artifact_uri="gs://my-bucket/new_saved_model/1/",
serving_container_image_uri="gcr.io/cloud-ml-pipeline-example/tensorflow-cpu"
)
endpoint.deploy(new_model, traffic_percentage=100)
まとめ
Google Cloud AI Platform を使用することで、機械学習モデルのトレーニングから展開までのプロセスを効率化できます。スケーラブルなインフラストラクチャと統合ツールセットにより、データサイエンティストは複雑な ML ワークフローを簡単に管理できます。
AI と機械学習についてさらに学びたい方は、以下の書籍がおすすめです:


