· ストレージとデータベース · 8 min read
BigTable の使い方:大規模 NoSQL データベースの管理
Google Cloud BigTable の基本的な使い方と効率的な管理方法を解説します。大規模データの取り扱いに最適なNoSQLデータベースの活用法を学びましょう。

BigTable とは
Google Cloud BigTable は、ペタバイト規模のデータを扱うことができる、フルマネージド型の NoSQL データベースサービスです。高スループット、低レイテンシーを実現し、大規模なデータ分析や機械学習のワークロードに適しています。
BigTable の主な特徴
- スケーラビリティ:数百ペタバイトまでシームレスに拡張可能
- 高パフォーマンス:ミリ秒単位の応答時間
- オープンソース HBase API との互換性
- フルマネージドサービス:インフラ管理の手間を削減
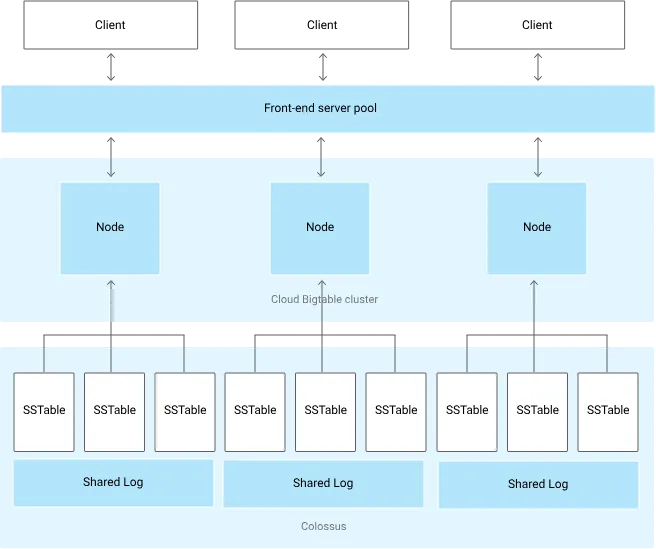
BigTable の使用開始方法
- Google Cloud Console にアクセス
- プロジェクトを選択または新規作成
- BigTable API を有効化
- インスタンスの作成
- テーブルの作成
データモデリングのベストプラクティス
BigTable では、効率的なデータモデリングが重要です。以下のポイントに注意しましょう。
- ロウキーの設計:データの分散と読み取りパフォーマンスに直結
- カラムファミリーの適切な使用:関連データのグループ化
- セルの大きさ:10MB以下に抑える
ロウキー設計のベストプラクティス
ホットスポッティングの回避
- ロウキーの先頭に一様に分散する値(ハッシュ値など)を使用
- タイムスタンプを逆にする(例:MAX_TIMESTAMP - timestamp)
関連データのグループ化
- 頻繁に一緒にアクセスされるデータを近くに配置
- 複合キーの使用(例:
user_id#post_id)
プレフィックス設計
- 効率的なスキャン操作のためのプレフィックスの活用
- 例:
device_type#device_id#timestamp
適切な粒度の選択
- データアクセスパターンに基づいて適切な粒度を決定
- 過度に細かい粒度は読み取りパフォーマンスに影響する可能性がある
カラムファミリーの効果的な利用
関連データのグループ化
- 同じアクセスパターンを持つデータを同じカラムファミリーに
- 例:ユーザープロフィールとユーザーアクティビティを別のカラムファミリーに
カラムファミリー数の最適化
- 一般的に、10個以下のカラムファミリーを推奨
- 多すぎるカラムファミリーはパフォーマンスに悪影響
動的なカラム名の活用
- 固定のカラム名ではなく、動的なカラム名を使用してデータを柔軟に格納
セルデータの設計
セルサイズの制限
- 10MB以下に抑えることを推奨
- 大きなデータはCloud Storageに保存し、参照を格納する
バージョニングの活用
- データの履歴管理にバージョニングを使用
- バージョン数は必要最小限に設定
TTL(Time to Live)の設定
- データの鮮度に応じてTTLを設定
- 古いデータを自動的に削除し、ストレージを最適化
パフォーマンスチューニング
BigTable のパフォーマンスを最適化するためのヒントをいくつか紹介します。
- クラスタのサイジング
- ワークロードの分散
- キャッシュの活用
- クエリの最適化
1. クラスタのサイジング
クラスタとは、BigTable を動かすためのコンピューターの集まりのことです。適切な数のコンピューターを用意することで、スムーズにデータを扱えるようになります。
コンピューターの数を決める
- どれくらいのデータを扱うかを考えて決めます
- データの読み書きの量に応じて調整します
- 目安として、1台のコンピューターで1秒間に約10,000回の処理ができます
自動で調整してくれる機能を使う
- 忙しい時は自動的にコンピューターを増やし、暇な時は減らしてくれます
- これにより、常に適切な数のコンピューターを維持できます
2. ワークロードの分散
一箇所に仕事が集中しないよう、うまく分散させることが大切です。
データの並べ方を工夫する
- データに付ける番号(キー)の付け方を工夫します
- 例えば、日付順に並べるのではなく、少しランダムになるよう工夫します
複数の場所でデータを扱う
- データを複数の場所に置いて、近い場所からアクセスできるようにします
- これにより、どこからアクセスしても速く取得できます
3. キャッシュの活用
キャッシュとは、よく使うデータを手元に置いておく仕組みです。これを使うと、データの取得が速くなります。
手元にデータを置く
- よく使うデータを一時的に保存しておきます
- 次に同じデータが必要になった時、すぐに取り出せます
外部のキャッシュシステムを使う
- Memcached(メムキャッシュド)という特別なキャッシュシステムを使います
- とても速くデータを取り出せるので、全体の速度が上がります
4. クエリの最適化
データの取り方を工夫することで、処理速度を上げることができます。
必要なデータだけを取る
- 全てのデータではなく、必要な部分だけを取り出します
- これにより、データを取る時間が短くなります
まとめて取る
- 1回ずつデータを取るのではなく、まとめて取ります
- これにより、データを取る回数が減り、全体の速度が上がります
同時に複数の処理をする
- 一つずつ順番に処理するのではなく、複数の処理を同時に行います
- これにより、全体の処理時間が短くなります
セキュリティと認証
BigTable のデータセキュリティを確保するための主な機能:
- IAM(Identity and Access Management)による細かなアクセス制御
- 保存データの暗号化
- 監査ログの活用
BigTable の運用管理
効率的な運用管理のためのポイントをご紹介します。
- モニタリングとアラートの設定
- バックアップと復元の戦略
- コスト最適化
まとめ
BigTable は大規模データ処理に強力なソリューションを提供します。適切な設計と運用により、ビジネスのデータニーズに効果的に対応できるでしょう。
BigTable をより深く理解したい方には、以下の公式ドキュメントがおすすめです。